채팅이 안 돼요!?
최근들어 채팅이 간헐적으로 먹통이 되는 순간이 발생하는 경우가 많아졌습니다. 채팅서버의 CPU를 확인해보니 Node가 CPU 100% 상태가 되어 있는 상황에 채팅이 안되는 상황이 발생하더군요. 아무래도 플로우의 클라우드 고객 유입이 많아지면서 단일 채팅서버로 구성되어 있는 부분에서 부하를 견디지 못한 것 같다고 판단을 했습니다. 하지만 어떠한 작업을 하더라도 확실한 원인 파악이 필요합니다 그래서 몇가지 확인 작업을 진행했습니다.
채팅서버는 하루동안 얼마나 많이 사용될까?
많은 사용자로 인한 부하라는 의심에 확신을 주기 위해 우선 1시간마다 Socket.io 에서 메시지의 호출이 이루어지는 체크를 하기 위해 메모리기반의 Redis를 붙이고 Socket.io 서버에 호출이 발생할때마다 Count를 올리는 로직을 붙였습니다. 기본적으로 운영중인 서버에 적용을 하는 작업은 더욱 더 신중하게 진행해야 하고 방어로직이 존재 해야하기 때문에 개발서버에서 많은 테스트를 진행하고 Redis서버가 죽더라도 Socket간의 통신에는 지장이 없도록 처리를 했습니다.
10시, 14시 ,15시 ~ 18시
![]()
10시, 14시 ,15시 ~ 18시 시간대에 가장 많은 Client와 Server간 통신이 이루어졌고 해당 시간대에 5분마다 Node의 CPU 상태를 체크하는 로직을 만들어서 Crontob을 활용해서 txt.파일의 저장하도록 했습니다 그렇게 하루가 지나고 시간대 별로 채팅서버에서 호출이 많이 일어난 시점과 CPU가 상승한 시점을 비교해보니 얼추 비슷하게 맞아떨어지는 것을 확인했습니다. 하지만 좀더 확실한 테스트가 필요해서 artillery.io 라는 가벼운 툴을 이용해서 부하테스트를 진행 했습니다.
config:
target: "http://localhost:3000"
# socketio:
# transports: ["websocket"]
phases:
- duration: 60
arrivalRate: 100
scenarios:
- engine: "socketio"
flow:
- emit:
channel: "sendMessage"
data: "helloTest"
- think: 5
Target은 내가 테스트할 서버의 주소를 지정해주었습니다. Phases는 테스트를 요청할 시간과 비율을 정하는부분 입니다. 60초동안 매초 100개의 요청을 보내도록 설정한 부분입니다.
간단하게 1초마다 100개의 connenct을 연결하고 sendMessage라는 채널에 Hello_Test라는 메시지를 보내는 부하테스트를 진행했습니다. 19시쯤 플로우의 채팅서버의 CPU상태와 동일한 15~30% 정도의 CPU사용량이 나타났습니다. 너무 많은 통신으로 인한 부하가 발생했다고 할 수 있는 자료와 테스트가 끝났으니 해결을 해보도록 하겠습니다.
부하를 분산시키는 여러가지 방법
첫번째로는 싱글스레드로 동작하는 Node를 멀티스레드 처럼 사용하는 방법이 있습니다. 바로 Node 자체에서 지원하는 Cluster 기능이죠 이 기능은 서버의 CPU코어의 수 만큼 Worker를 만들어 여러개의 서버를 띄우는 것과 비슷한 성능을 하도록 만들어 줍니다.
두번째로는 서버내의 포트를 여러개로 열고 포트마다 노드서버를 실행시켜서 사용자가 들어 올때마다 서버를 순차적으로 나눠주어서 서버의 부하를 줄이는 방법입니다.
 출처 : https://msandbu.org/deep-dive-azure-load-balancer/
출처 : https://msandbu.org/deep-dive-azure-load-balancer/
서버의 관계없이 Socket의 누락이 발생하지 않도록 하는방법
Socket.io의 경우 동일한 서버에 접속한 상태가 아니라면 클라이언트간의 통신이 안되는 경우가 발생하는데 해당 부분을 처리하기 위해서는 Redis의 Pub/Sub 기능을 활용해야 한다. 즉 1번서버에 접속한 사용자와 2번서버에 접속한 사용자간의 데이터 통신이 가능해집니다.
const redis = require('socket.io-redis');
io.adapter(redis({ host: 'localhost', port: 6379 }));
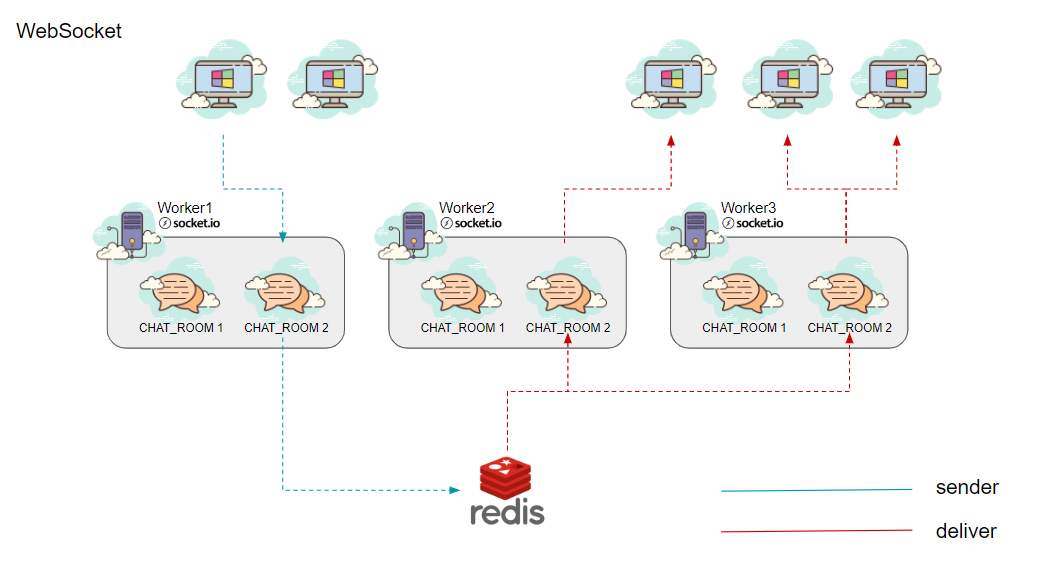
모듈화가 굉장히 잘되어져 있어 해당 소스만으로도 처리가 가능해지지만 정확히 이해를 하고싶어서 아래와 같은 Redis가 각각 다른 프로세스에서 실행된 Socket.io간의 통신이 이루어지는 구조를 한번 그려봤습니다.

Redis를 이용해서 이제 각각 다른 프로세스의 소켓간의 통신이 가능하도록 처리를 했졌습니다. 저는 로드밸런싱을 이용하지 않고 Node에서 제공해주는 클러스터를 이용해서 부하분산을 처리 했습니다.
Socket.io TransPort [Polling, WebSocket] 에 따른 처리방법
Node의 Cluster를 이용해서 CPU 코어 수 만큼의 Worker를 만드는데는 성공했지만 또 다른 문제가 발생했습니다. 다름이 아니라 Polling 처리를 이용해서 연결을 진행하고 이후에 WebSocket으로 업그레이드를 진행하는 Socket.io의 로직으로 인해 문제가 생겼습니다.
Polling 처리는 결국 Http로 계속해서 요청을 보내고 그에 따른 응답을 받아야 하는데 계속해서 접속되는 Worker가 변경되면서 이에 맞는 응답을 보내주지 못하면서 오류가 발생했습니다.
해당 오류는 단순하게 클라이언트단 이나 서버에서 WebSocket방식으로만 요청을 받로록 설정하면 되지만 플로우의 경우 WebSocket 방식만을 사용하면 생기는 문제가 있습니다.
Notices
너무 글이 길어지고 늦은시간이라… 1편과 2편으로 나누어서 진행하겠습니다.